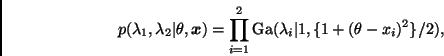Como se mencionó en la Sección 1.2, la función de
verosimilitud inducida por una distribución Cauchy puede tener una forma
complicada incluso cuando se tienen sólo dos observaciones. Por fortuna,
en este caso es posible utilizar el método de variables latentes,
aprovechando la representación (4), y obtener así una muestra
de la distribución final de ![]() a través del algoritmo de Gibbs.
a través del algoritmo de Gibbs.
Supongamos que a cada observación ![]() ,
, ![]() se le asocia una variable
se le asocia una variable
![]() ,
, ![]() , respectivamente, de tal forma que
, respectivamente, de tal forma que
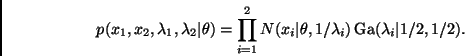
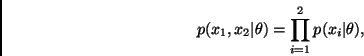
Por otro lado, dado que
![]() se tiene que
se tiene que
Las densidades condicionales completas (13) y (14) pueden
ahora utilizarse en el muestreo de Gibbs. En este caso se corrió
el algoritmo durante 1100 iteraciones, de las cuales se tomaron las primeras
100 como periodo de calentamiento, para generar una muestra de tamaño
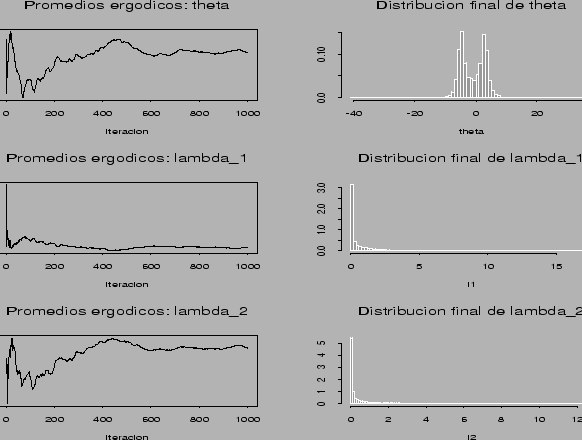
![]() . La Figura 4 presenta los promedios ergódicos de las
medias muestrales de
. La Figura 4 presenta los promedios ergódicos de las
medias muestrales de ![]() ,
, ![]() y
y ![]() , así como
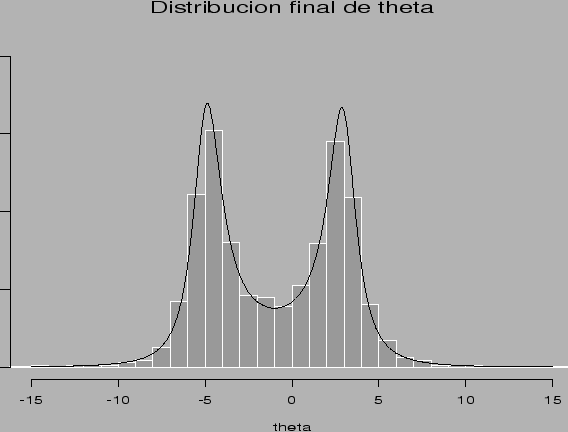
los histogramas correspondientes. En la Figura 5 se muestra el
histograma para
, así como
los histogramas correspondientes. En la Figura 5 se muestra el
histograma para ![]() junto con una estimación de la
función de densidad
junto con una estimación de la
función de densidad
![]() . Como era de esperarse,
esta densidad es bimodal (con modas en
. Como era de esperarse,
esta densidad es bimodal (con modas en
![]() y
y
![]() ). Por otra parte,
). Por otra parte,
![]() y
y
![]() , aunque debe
señalarse que la información proporcionada por la media y la varianza
no es muy relevante en este caso.
, aunque debe
señalarse que la información proporcionada por la media y la varianza
no es muy relevante en este caso.