Consideremos una serie de experimentos
![]() ,
donde
,
donde ![]() produce observaciones
produce observaciones ![]() cuya distribución depende del
parámetro
cuya distribución depende del
parámetro
![]() . De esta manera, cada
. De esta manera, cada ![]() tiene asociada una
función de verosimilitud
tiene asociada una
función de verosimilitud
![]() . (Cabe mencionar
que los métodos descritos en esta sección son también aplicables a datos
observacionales que tengan una estructura jerárquica.)
. (Cabe mencionar
que los métodos descritos en esta sección son también aplicables a datos
observacionales que tengan una estructura jerárquica.)
Comentario. Algunos de los parámetros pueden ser comunes a todos los
experimentos. Por ejemplo, cada vector ![]() puede ser una muestra de
observaciones de una distribución Normal con media
puede ser una muestra de
observaciones de una distribución Normal con media ![]() y varianza
común
y varianza
común ![]() , de manera que
, de manera que
![]() .
.
Si no contamos con información que nos permita distinguir cualquiera de los
parámetros
![]() de los otros (aparte de las observaciones
de los otros (aparte de las observaciones
![]() ), y si no es razonable establecer algún orden o agrupamiento de
los parámetros, entonces debemos suponer alguna forma de simetría entre
éstos. Dicha simetría debe verse reflejada en la distribución
inicial de los parámetros
), y si no es razonable establecer algún orden o agrupamiento de
los parámetros, entonces debemos suponer alguna forma de simetría entre
éstos. Dicha simetría debe verse reflejada en la distribución
inicial de los parámetros
![]() y se representa
probabilísticamente a través del concepto de intercambiabilidad
discutido en la Sección 2.2. De esta manera,
y se representa
probabilísticamente a través del concepto de intercambiabilidad
discutido en la Sección 2.2. De esta manera,
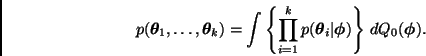
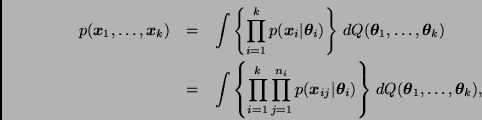
A manera de resumen, podemos decir que un modelo jerárquico tiene la siguiente estructura:
Nivel I. (Observaciones)
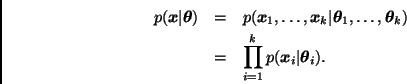
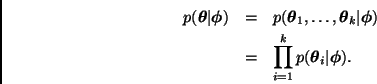
Es claro que estas ideas pueden generalizarse para construir modelos jerárquicos con más de tres niveles. Sin embargo, con el fin de facilitar la exposición, en este trabajo nos concentraremos en modelos de tres niveles.
Covariables
En ocasiones se cuenta con información adicional en forma de
covariables
![]() , de manera que el conjunto de
observaciones está dado por
, de manera que el conjunto de
observaciones está dado por
![]() .
La forma usual de modelar la intercambiabilidad de los parámetros en
presencia de covariables es a través del concepto de independencia
condicional,
.
La forma usual de modelar la intercambiabilidad de los parámetros en
presencia de covariables es a través del concepto de independencia
condicional,
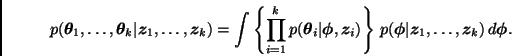
En esencia, esto supone cierta forma de intercambiabilidad parcial (ver Sección 2.2.2).