Inferencia sobre ![]()
De acuerdo con los resultados de la sección anterior, la distribución
final de ![]() es
es
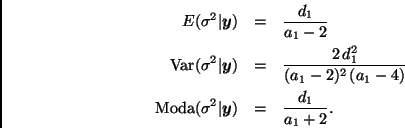
Estas cantidades pueden servir de base para hacer inferencias sobre
![]() . También es posible construir intervalos de máxima densidad
o simplemente reportar algunos percentiles de la distribución final de
. También es posible construir intervalos de máxima densidad
o simplemente reportar algunos percentiles de la distribución final de
![]() .
.
Notemos que si se utiliza la distribución de referencia estas expresiones se reducen a
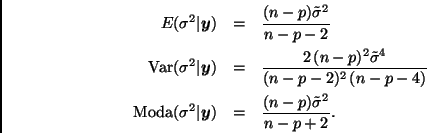
Inferencia sobre ![]()
La distribución final de ![]() está dada por
(7). En particular,
está dada por
(7). En particular,
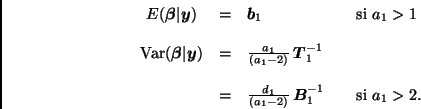
Por otro lado, si se utiliza la distribución de referencia entonces
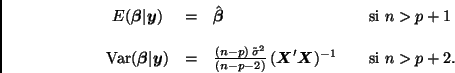
Como en el caso anterior, estas cantidades pueden servir de base para hacer
inferencias sobre ![]() . Notemos, sin embargo, que en este caso el
interés se centra generalmente en combinaciones lineales de las entradas del
vector
. Notemos, sin embargo, que en este caso el
interés se centra generalmente en combinaciones lineales de las entradas del
vector ![]() .
.
Sea
![]() , donde
, donde ![]() es una
matriz
es una
matriz ![]() de rango
de rango
![]() . Entonces
. Entonces
Supongamos, por ejemplo, que ![]() y
y
![]() para alguna
para alguna ![]() .
Entonces
.
Entonces
![]() .
En este caso
.
En este caso
![]() y
y
![]() , donde
, donde ![]() es la entrada
es la entrada ![]() de la matriz
de la matriz
![]() . Por lo tanto,
. Por lo tanto,
Predicción
Supongamos que se desea predecir ![]() , un nuevo valor de la
variable de respuesta, dado el vector de covariables
, un nuevo valor de la
variable de respuesta, dado el vector de covariables
![]() . De acuerdo con el modelo,
. De acuerdo con el modelo,
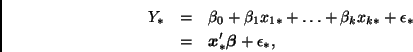
El problema de predicción puede abordarse de dos maneras:
(a) Inferencia sobre ![]() . El parámetro
. El parámetro ![]() , que
corresponde al valor esperado de la observación futura
, que
corresponde al valor esperado de la observación futura ![]() , no es más
que una combinación lineal de los coeficientes de regresión.
, no es más
que una combinación lineal de los coeficientes de regresión.
Sea ![]() y
y
![]() . Entonces
. Entonces
![]() ,
,
![]() y
y
![]() , por lo que
, por lo que
En particular, si se utiliza la distribución de referencia entonces
(b) Inferencia sobre ![]() . En este caso interesa calcular la
distribución predictiva final para
. En este caso interesa calcular la
distribución predictiva final para ![]() ,
,
Recordemos primero que
![]() .
Trabajando condicionalmente en
.
Trabajando condicionalmente en ![]() , tenemos que
, tenemos que ![]() y
y
![]() son independientes y
son independientes y
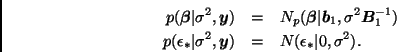
Esto implica que
Finalmente, integrando con respecto a la distribución final de ![]() ,
,
Si se utiliza la distribución de referencia entonces la distribución
predictiva final toma la forma