Supongamos que se tiene una densidad
![]() de la
cual es posible simular observaciones fácilmente, pero que se requiere
una muestra de la densidad
de la
cual es posible simular observaciones fácilmente, pero que se requiere
una muestra de la densidad
![]() Caso 1. Si existe una constante
Caso 1. Si existe una constante ![]() tal que
tal que
![]() para todo
para todo
![]() ,
entonces es posible utilizar el método de aceptación y rechazo para
generar variables aleatorias (ver Ripley 1987). El algoritmo es el
siguiente:
,
entonces es posible utilizar el método de aceptación y rechazo para
generar variables aleatorias (ver Ripley 1987). El algoritmo es el
siguiente:
1. generar una observación
![]() de
de
![]() ;
;
2. generar una variable ![]() ;
;
3. si
![]() ,
aceptar
,
aceptar
![]() como una observación de
como una observación de
![]() ; en caso contrario, repetir los pasos 1 a 3.
; en caso contrario, repetir los pasos 1 a 3.
Cabe señalar que, dada una muestra de tamaño ![]() de
de
![]() ,
el valor esperado para el tamaño de la correspondiente muestra de
,
el valor esperado para el tamaño de la correspondiente muestra de
![]() es
es
![]() Caso 2. Si no existe la cota del punto anterior,
o ésta no puede encontrarse fácilmente, entonces podemos obtener
muestras aproximadas de
Caso 2. Si no existe la cota del punto anterior,
o ésta no puede encontrarse fácilmente, entonces podemos obtener
muestras aproximadas de
![]() de la siguiente manera.
Supongamos que
de la siguiente manera.
Supongamos que
![]() es una muestra de
es una muestra de
![]() . Sea
. Sea
A diferencia del caso anterior, aquí es posible muestrear con
remplazo, por lo que la muestra generada puede ser tan grande como
se quiera. Es claro, sin embargo, que la aproximación será más
adecuada a medida que
![]() se parezca más a
se parezca más a
![]() .
.
Comentario. Existe una dualidad muy interesante entre una muestra
dada y la distribución que la genera. Por un lado, la distribución
permite generar la muestra; por otro lado, dada la muestra en principio
es posible recrear la distribución que la generó (al menos
aproximadamente). Este argumento, junto con los métodos discutidos en
esta sección, sugiere una versión ``muestral'' del teorema de Bayes
al identificar a
![]() y
y
![]() con
con
![]() y
y
![]() , respectivamente,
de manera que
, respectivamente,
de manera que
![]() .
.
![]() Si existe el estimador de máxima verosimilitud,
Si existe el estimador de máxima verosimilitud,
![]() , entonces podemos tomar
, entonces podemos tomar
![]() . Es este caso el teorema de Bayes
toma una forma muy sencilla: una observación
. Es este caso el teorema de Bayes
toma una forma muy sencilla: una observación
![]() en
la muestra de la distribución inicial
en
la muestra de la distribución inicial
![]() es aceptada
como una observación de la distribución final
es aceptada
como una observación de la distribución final
![]() con probabilidad
con probabilidad

![]() Si la cota
Si la cota ![]() no está disponible, dada
una muestra
no está disponible, dada
una muestra
![]() de la
distribución inicial
de la
distribución inicial
![]() podemos remuestrear
observaciones
podemos remuestrear
observaciones
![]() de acuerdo con la
distribución discreta
de acuerdo con la
distribución discreta
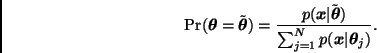
En ambos casos los valores de
![]() cuya verosimilitud es
alta tienen una mayor probabilidad de quedar representados en la
muestra de la distribución final.
cuya verosimilitud es
alta tienen una mayor probabilidad de quedar representados en la
muestra de la distribución final.