En el enfoque Bayesiano de la Estadística, la
incertidumbre presente en un modelo dado,
![]() , es
representada a través de una distribución de probabilidad
, es
representada a través de una distribución de probabilidad
![]() sobre los posibles valores del parámetro desconocido
sobre los posibles valores del parámetro desconocido
![]() (típicamente multidimensional) que define al modelo.
El Teorema de Bayes,
(típicamente multidimensional) que define al modelo.
El Teorema de Bayes,
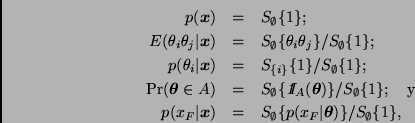
En la práctica es común que la dimensión de
![]() sea muy
grande. Por otro lado, excepto en aplicaciones muy sencillas tanto
sea muy
grande. Por otro lado, excepto en aplicaciones muy sencillas tanto
![]() como
como
![]() pueden llegar a
tener formas muy complicadas. En la gran mayoría de los problemas las
integrales requeridas no pueden resolverse analíticamente, por lo que
es necesario contar con métodos numéricos eficientes que permitan
calcular o aproximar integrales en varias dimensiones.
pueden llegar a
tener formas muy complicadas. En la gran mayoría de los problemas las
integrales requeridas no pueden resolverse analíticamente, por lo que
es necesario contar con métodos numéricos eficientes que permitan
calcular o aproximar integrales en varias dimensiones.
El propósito de estas notas es revisar de manera general algunos de los métodos clásicos para calcular integrales, tales como la aproximación de Laplace, cuadratura (integración numérica) y el método de Monte Carlo, así como discutir algunas de las técnicas de integración desarrolladas durante los últimos años y conocidas con el nombre genérico de técnicas de Monte Carlo vía cadenas de Markov. El lector interesado en el enfoque Bayesiano de la Estadística o en aspectos específicos de los métodos aquí discutidos puede consultar los libros de Bernardo y Smith (1994) y O'Hagan (1994), así como las referencias que ahí se incluyen.
En términos generales, los métodos antes mencionados serán más
eficientes y darán resultados más precisos en la medida en que la
distribución final sea más parecida a una distribución normal. Es por
esta razón que en la mayoría de los casos resulta conveniente trabajar
en términos de una reparametrización del modelo, de manera que cada uno
de los nuevos parámetros tome valores en todo ![]() y su distribución
final sea aproximadamente normal. También es importante que la
correlación final entre los nuevos parámetros no sea muy alta.
y su distribución
final sea aproximadamente normal. También es importante que la
correlación final entre los nuevos parámetros no sea muy alta.
En lo que resta de esta sección describiremos dos problemas que nos servirán para ilustrar y comparar los métodos discutidos en estas notas. Algunos de estos métodos han sido instrumentados en el lenguaje S de S-Plus. El código correspondiente, así como los resultados principales, pueden encontrarse en los apéndices al final de este trabajo.